動機
大学の人工知能に関する講義で、自ら判別できそうなデータを探し、それをAIで判別する課題が出ました。
そのため私はサカナクションに関することをしようと考え、「曲がくるりかサカナクションかAIで判別」するお題に決めました。
データ
まずデータとして、
- くるり
- 30曲
- ベスト オブ くるり / TOWER OF MUSIC LOVER
- 30曲
- サカナクション
- 102曲
- リミックスを除いた全曲
- 102曲
を用意しました。
テスト用データ
学習用とテスト用のデータの二つに、適当に分けました。
テスト用データは以下の曲にしました。
-
アンダー
-
マッチとピーナッツ
-
シーラカンスと僕(リアレンジ番も含む)
-
ナイロンの糸
-
モス
-
新宝島(リアレンジ番も含む)
-
サンプル
-
モノクロトウキョー
-
白波トップウォーター(リアレンジ番も含む)
-
ティーンエイジ
-
BIRTHDAY
-
Giant Fish
-
BABY I LOVE YOU
-
ハローグッバイ
学習・分析
大まかな分析手順として、
- 曲ごとに時間が違うため、曲をカットする
- 前処理(メルスペクトログラムまたはMFCC)をして画像として扱う
- ResNet のチャネル数や出力数を2クラスに設定する
- 学習させ、分析する
という風に行いました。
前処理
データの前処理を複数の方法で行い、精度の差を調べました。
適切な曲の分割サイズ
曲ごとに長さが異なるため、分割して時間をそろえる必要があります。
どの分割にしたら精度がよくなるかわからないため、20 秒、60 秒、180 秒の三つの値を「メルスペクトログラムから更にデシベルスケールに変換した画像」で検証しました。分割されている秒数が異なるため、テスト用の曲のデータも異なり、正確な比較ではないかもしれないが、以下のようになりました。
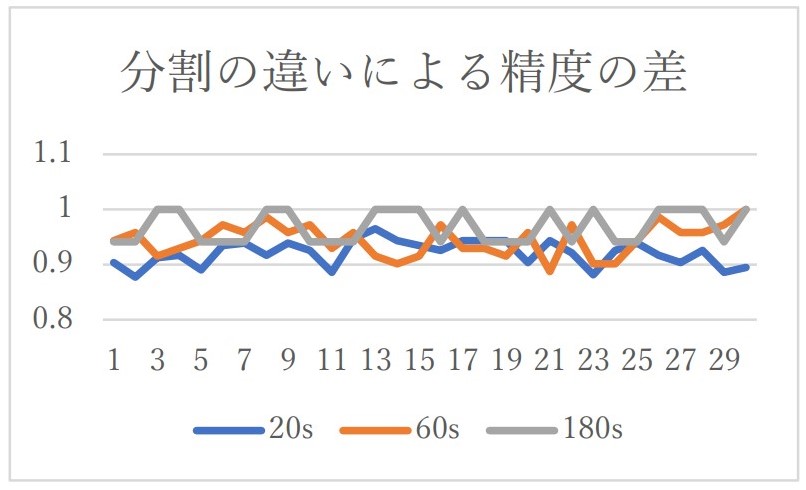
秒数が長いほど精度がよい傾向になりました。
また 20 秒は実行にとても時間がかかり、180 秒であるとサンプル数が少なく、精度の差がわからなかったです。よって以降のデータは 60 秒に分割して行います。
精度の良い音響特徴量
音声データでは、データを直接処理する場合もあるが、「メルスペクトログラム」と「MFCC(メル周波数ケプストラム係数)」などのフーリエ変換したスペクトルを基に考えることが多いです。
「メルスペクトログラムから更にデシベルスケールに変換した画像」と「MFCCによる画像」の2パターンを 60 秒で行ってみました。
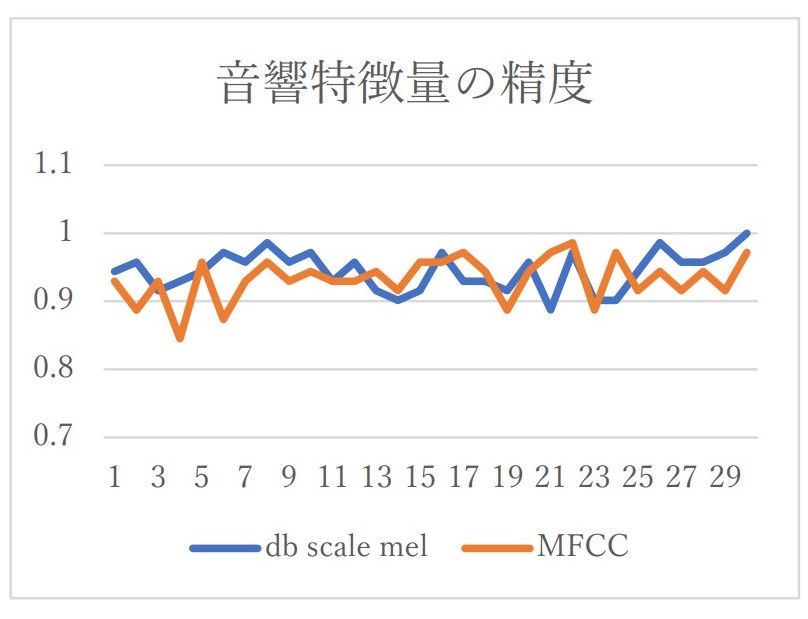
各平均が 0.945, 0.933 になりメルスペクトログラムの方が、若干精度がよいことが分かりました。
情報を限定させる方法
ここまでは音の分析ではよくある方法なのですが、なにか曲の分析に特化した前処理がないか考え以下のやり方を行いました。
仮説
曲では、和音やボーカルの声が中心から聞こえています。それらはアーティストの特色になっています。それとは反対に、曲ごとに違うメロディーを用いていることが多く、それらは左右に散らばっており、分析にはあまり必要のないデータです。
以上からなるべくアーティストの特色が出やすくなるように、中心に集まっている音のみにすると、精度が上がるのではないかと考えました。
手法
- ステレオの音を分割する。
- 右の音を逆位相にして、二つを合成させる。(ボーカルのような中心の音がなくなる。)
- 元のステレオの音を分割し、合成させる。
- 2 と 3 で生成したモノラル音を合成させる。
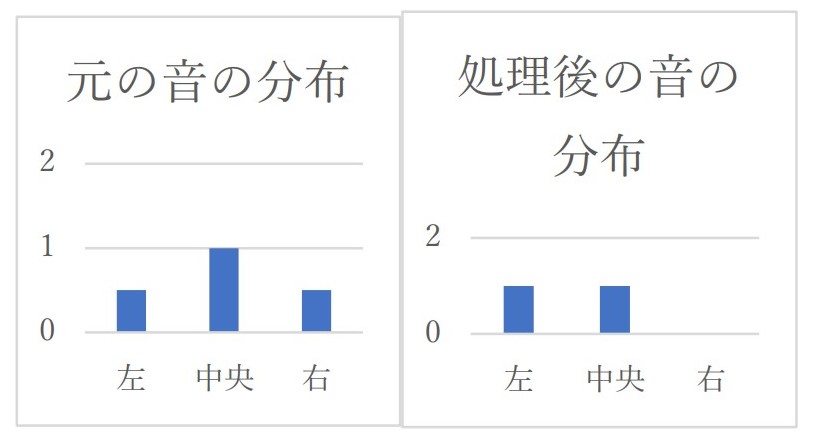
すると右側のみの音が完全に聞こえなくなり、左と中心の音が強調されて聞こえます。
以下がイメージ図です。
結果
工夫する前と比べて精度が低くなり、平均が0.922371438 で、仮説に反した結果となりました。
また曲に依存せず、分割されたデータ単位でランダムに訓練用・テスト用のデータを取得して行った場合、工夫した方の精度が 1 に速く収束し、学習する速度は速くなるという結果となりました。
以上から、もっと情報を上手く限定して周波数や楽器ごとに分けることができれば、精度がよく学習する速度も速められ、よい前処理になった可能性があります。
まとめ
大体90%以上の精度で判別できており、意外と精度が高くてびっくりしました。
今度新アルバムがリリースされるので、新しい曲はサカナクションの曲として判断されるのか試したいです。
また2アーティストのみであったり、データ数の差があったり、モデルが適切でない可能性もあり、いつか時間があるときにもっと正確な分析を行いたいです。